
Nektar’s REZOLVE-AA Readout: Model-Dependent Medicine
High “patient decision” attrition routed into MI/MMRM, plus a fragile placebo arm, may have inflated Rezpeg’s Week 36 mean effect despite a SALT≤20 benchmark miss.


What I Modeled vs. What Nektar Delivered
When I modeled Nektar’s NKTR 0.00%↑ REZOLVE-AA outcomes back in November, I was doing so under the assumption that a normal number of patients would withdraw from the study and that Nektar would present ITT data. Neither was the case.
Still, even after removing four patients in a post hoc analysis, Rezpeg’s SALT≤ 20 result (the standard primary endpoint in past AA induction pivotal studies) fell meaningfully short of management’s own expectations of low-dose JAK-like efficacy.
When comparing the outcomes from REZOLVE-AA to the approved JAKs, we see low-dose Olumiant as the appropriate benchmark. In its 2 Phase III trials, the approved 2 mg dose of Olumiant showed that 15% to 16% of patients achieved SALT 20 on a placebo-adjusted basis at week 36, and the mean improvement in SALT scores from baseline was 24% to 26% on a placebo-adjusted basis. Note that the placebo response rate in these trials is relatively low at 3% to 5% for the SALT 20 endpoint and 4% to 9% on the mean reduction endpoint. Because of our differentiated mechanism of action compared to the JAK inhibitors and our safety profile, we see a very clear market opportunity for Rezpeg in alopecia areata if Rezpeg achieves these benchmarks.
Source: Nektar’s Q3 earnings call
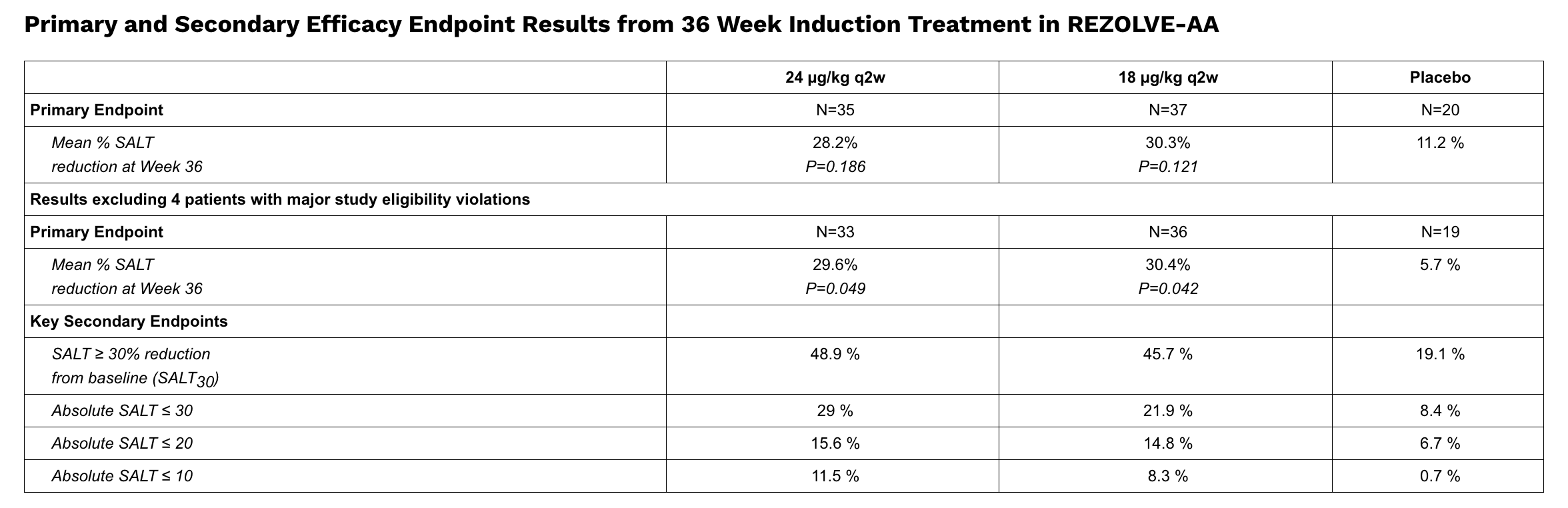
Indeed, Rezpeg’s SALT≤ 20 placebo-adjusted delta of ~8-9 points fell materially short of “15-16” and came within inches of my “no clinically meaningful benefit” estimate.
On the other hand, Rezpeg’s Week 36 placebo-adjusted mean %SALT reduction (REZOLVE-AA’s powered primary endpoint) was admittedly much stronger than I expected, but there were major caveats.
Why the Week 36 Mean Is Hard to Trust: Attrition, Estimand Mapping, and Model Dependence
Interpretation is complicated by unusually high pre–Week 36 discontinuation that was largely coded as “Withdrawal by Subject/Patient Decision” and, under the prespecified estimand, was not treated as treatment failure. Those outcomes were instead set to missing, imputed via multiple imputation, and the Week 36 continuous endpoint was estimated with MMRM. When discontinuation is both common and plausibly linked to limited early improvement in a delayed-response disease, the Week 36 mean becomes highly sensitive to MAR-based assumptions because it is increasingly driven by the subset that remains observed.
My key point is not that MMRM is inherently “bad.” It’s that REZOLVE-AA’s dropout pattern makes the Week 36 mean hinge on assumptions that cannot be stress-tested from the public deck alone. In that setting, the most plausible direction of error is upward: if “patient decision” discontinuers were enriched for slow/nonresponders (as management’s “limited early improvement” comments suggest), then MI/MMRM would tend to impute Week 36 outcomes that are too favorable, overstating the true placebo-adjusted mean separation.
Let’s break it down:
A whopping 29.3% of patients discontinued before Week 36 via “Withdrawal by Subject/Patient Decision.” In fact, by Week 36, REZOLVE-AA was left with only 11 placebo patients.
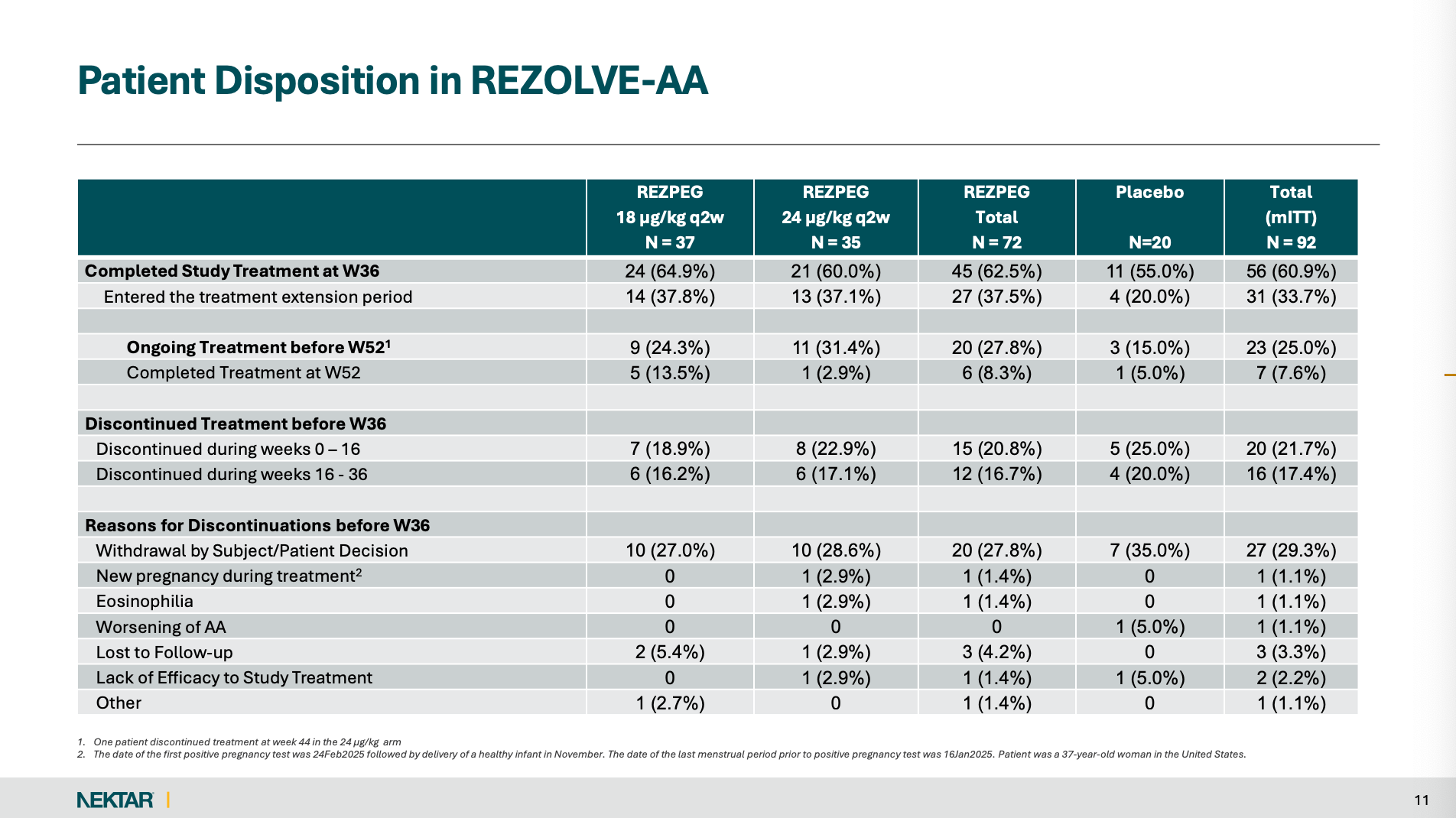
This amount of withdrawal is HIGHLY unusual in the context of past AA trials, but not in the context of Rezpeg.
For example, in Pfizer’s ALLEGRO-2b/3 (ritlecitinib), 104/718 (~14.5%) discontinued treatment, and 34/718 (~4.7%) withdrew. In Eli Lilly’s BRAVE-AA1/AA2, 598/654 (91.4%) and 490/546 (89.7%) completed 36 weeks.
The question that follows is how were all these missing patients treated?
Like it did following Phase 2 atopic dermatitis data (which also relied relatively heavily on modeling assumptions), Nektar dedicated an entire slide to its “Statistical Analysis Methodology” to answer this.

Notice that the primary estimand forces NONRESPONDER only for (1) prohibited AA meds or (2) discontinuation “due to lack of efficacy” (BLOCF for continuous, NRI for binary).
For discontinuations “due to other reasons,” data are set to missing, then missing data are imputed using multiple imputation. Continuous endpoints (mean %SALT reduction) are analyzed with MMRM.
As a result, the biggest dropout bucket in REZOLVE-AA (“patient decision”) is not automatically counted as failure. It flows into MI/MMRM, which is vulnerable if those dropouts are outcome-informative (for example, slow or nonresponders leaving).
Rezpeg is generally well-tolerated, so why are so many patients in these trials dropping out? Bear in mind that it is probably pretty easy to “tell” if you are on Rezpeg versus a placebo.
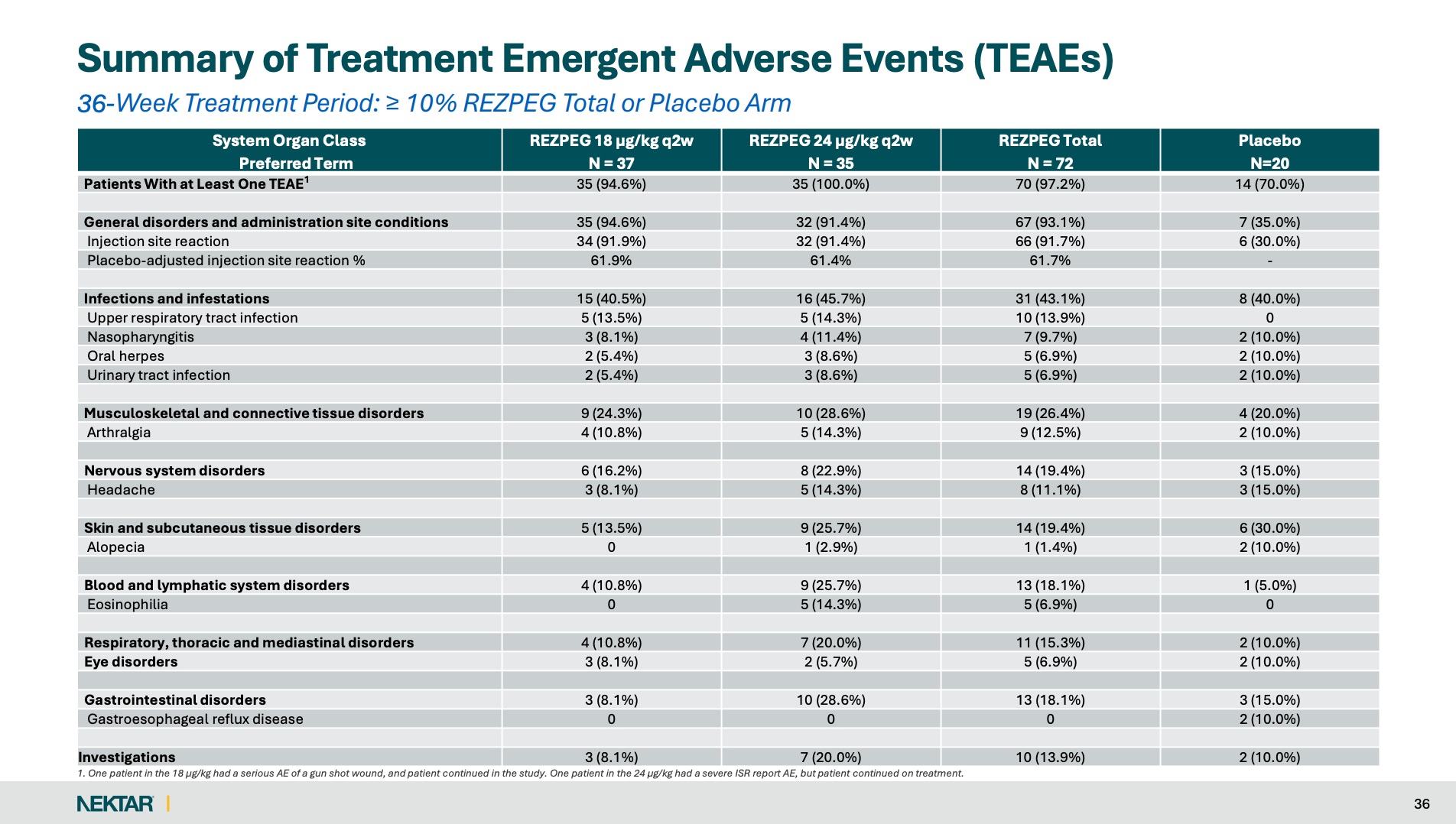
Indeed, over 9 in 10 Rezpeg patients experience injection site reactions, or ISRs, versus just 30% of placebo patients, possibly unblinding patients.
Think about it. This isn’t pancreatic cancer. AA patients can see the results for themselves in the mirror. A patient who suspects they are on the active drug but sees no hair growth is far more likely to quit than any super-responder.
The combination of near-universal ISR signal + minimal AE-coded discontinuation + a massive “patient decision” bucket is consistent with tolerability/unblinding pressure being reclassified into a broad category. This is exactly the kind of mechanism that can violate MAR assumptions in MI/MMRM.
Historically, AA programs typically anchored on binary responder endpoints like SALT≤20 often default to a conservative framing where most missing categorical outcomes are treated as NONRESPONSE.
For instance, in ALLEGRO-2b/3’s protocol, missing data for reasons not related to COVID-19 are assumed to be nonresponders, with separate COVID handling and sensitivity analyses. In the BRAVE-AA trials, the NEJM publication reports multiple imputation for missing data in the main analyses, but it also explicitly provides (in the supplement) the prespecified original SAP alternative where nonresponse is imputed for missing categorical outcomes. For continuous outcomes, it shows results under MI, with a prespecified modified “last observation carried forward,” or LOCF, approach reported in the supplement.
The key nuance is that REZOLVE-AA’s primary is “continuous mean %SALT reduction,” where the “standard” is not a literal NRI rule, but rather how discontinuations are mapped into the estimand (treatment-failure imputation like BLOCF vs. treating them as missing under MAR and modeling via MI/MMRM), because that decision becomes far more consequential when discontinuations are both frequent and potentially outcome-informative.
A “survivorship + imputation” inflation mechanism is plausible for the following four reasons:
Rezpeg patients are at risk of functional unblinding due to unusually high ISR rates: A large adverse-event signal (in this case, ISRs) that is highly imbalanced (~92% vs 30%) can create functional unblinding, increasing the likelihood that withdrawal decisions differ by arm and correlate with perceived response (or lack of).
High pre–Week 36 discontinuation concentrated in a non-penalized bucket. REZOLVE-AA had 36/92 (39.1%) discontinue treatment before Week 36, and the dominant reason was “Withdrawal by Subject/Patient Decision” (27/92; 29.3%), while only 2/92 (2.2%) were coded as “lack of efficacy.”
The primary estimand routes most of that bucket into MI/MMRM rather than failure. The SAP states that only prohibited AA meds or discontinuation “due to lack of efficacy” are forced to NONRESPONDER (BLOCF for the continuous endpoint), while discontinuations “due to other reasons” have data set to missing, with missingness handled by multiple imputation, and the Week 36 mean %SALT reduction is estimated via MMRM.
The company frames the response as delayed: The press release says the majority of patients experienced hair growth at Week 16 or later. That is exactly the setup where early “patient decision” withdrawals can be outcome-informative, because patients with no or minimal early improvement have a higher propensity to drop than patients with any regrowth. If many early dropouts fall into that no/low early improvement group, but the primary estimand treats them as missing and imputes under MAR (MI/MMRM), their Week 36 values could be pulled toward the arm’s modeled trajectory (increasingly determined by those who remain observed), rather than being treated as treatment failures.
Bear in mind that “lack of efficacy” is often under-coded in clinical trials because it is a narrow, investigator-recorded category, while “Withdrawal by Subject/Patient Decision” is a broad catch-all.
Moving on, placebo attrition was also extreme:
9/20 (45%) discontinued before Week 36, and those missing outcomes were handled under the same MI/MMRM framework. That means the Week 36 placebo mean is materially model-dependent, and any shift in placebo directly alters the drug–placebo delta.
This isn’t just another theory of mine. The placebo arm is clearly statistically fragile. Nektar disclosed that excluding just one placebo patient (post hoc) shifted placebo performance by 5.5%, a swing large enough for the company to report nominal significance in that post hoc mITT analysis. In other words, REZOLVE-AA’s primary endpoint was numerically hostage to a tiny placebo completor set and a placebo mean demonstrably movable by a single subject.
Alternatively, one can argue that this dropout pattern could have hurt Rezpeg (blunting its true effect).
However, for MI/MMRM to understate Rezpeg, missing patients must, on average, have Week 36 outcomes better than the MAR-based imputation predicts.
While possible in theory, it is less consistent with the trial’s own signals that discontinuation tracked limited early improvement. Management said more discontinuations occurred before Week 16 than after, and that 75% of “patient decision” discontinuers left before achieving a 30% SALT reduction (which includes zero response and minimal response).
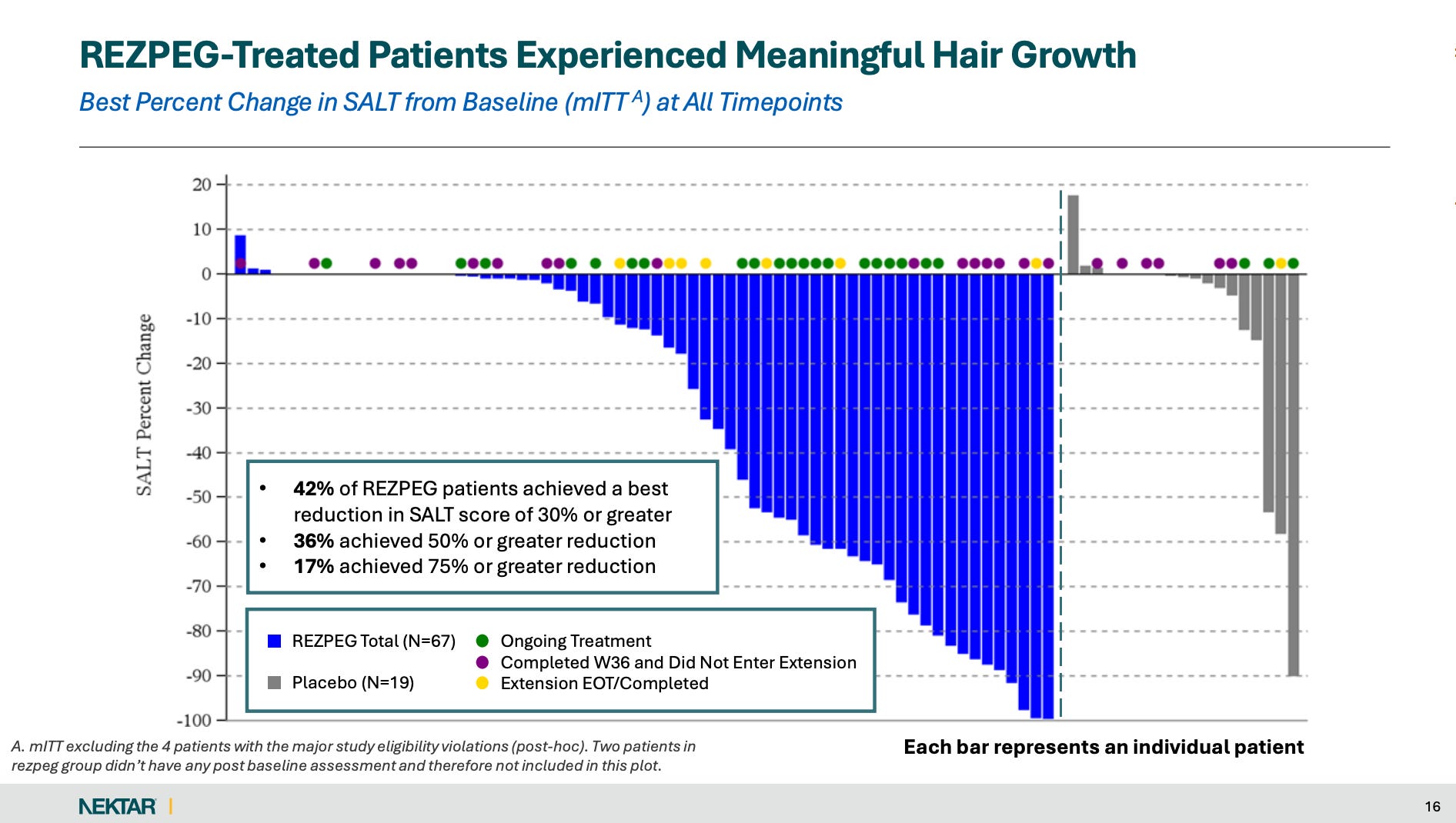
The waterfall visualization (below) points in the same direction: it is labeled as “Best Percent Change in SALT from Baseline at All Timepoints,” and patients without Week 36 assessments (the bars with no dots) are visually concentrated among the minimal-improvement bars (towards the left of the axis).
Other Interpretability Problems
Beyond the unusually high withdrawal-driven missingness (and model dependence), the dataset has multiple fragility layers, and Nektar’s presentation of the data is a mess.
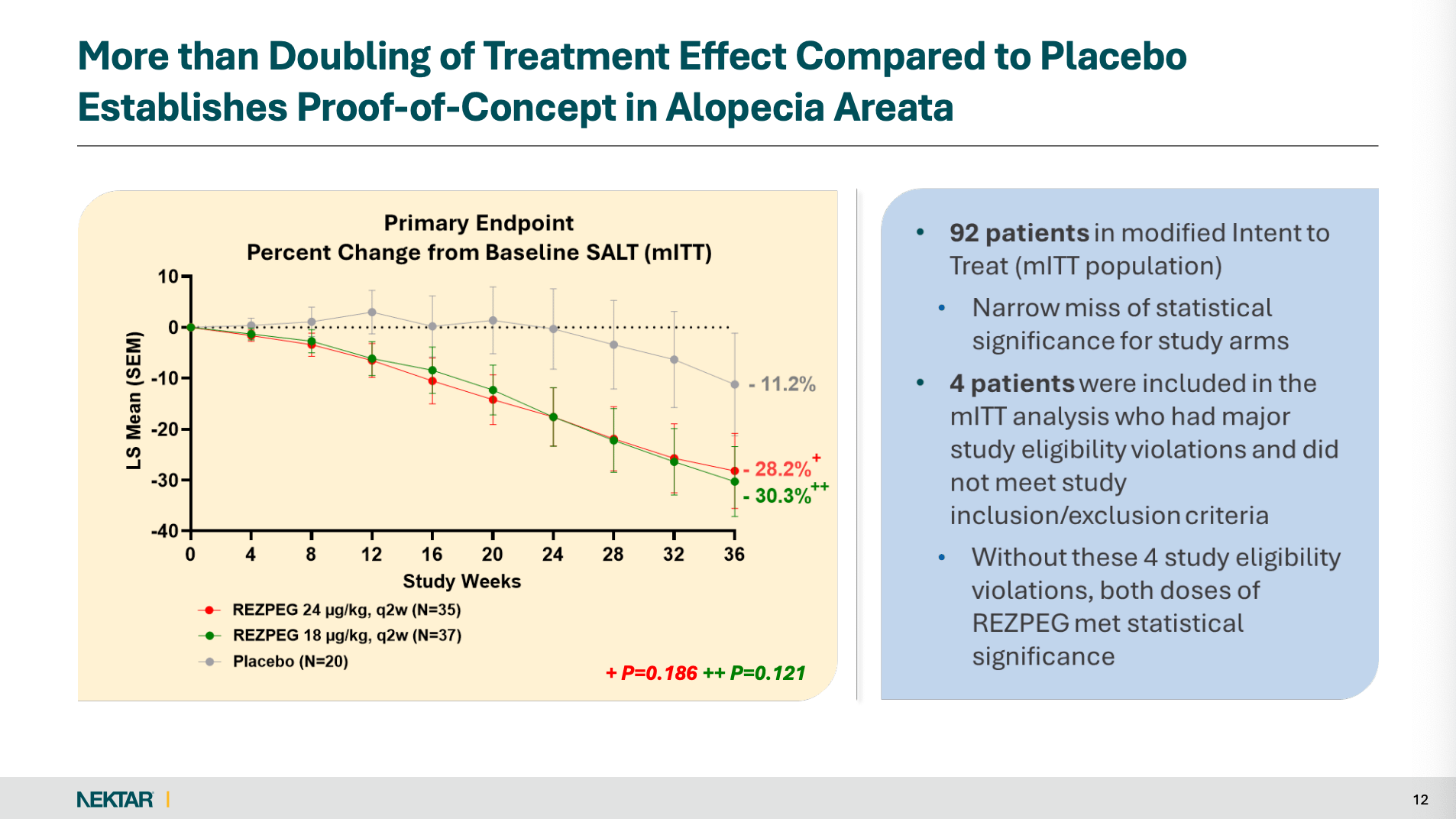
mITT is not pure ITT: The company states the mITT analysis excludes 2 patients enrolled at a site that was closed for GCP compliance issues.
Heavy Poland concentration: Patients were predominantly recruited from Poland (62%). Given the above known issues, it’s difficult to “trust” the results.
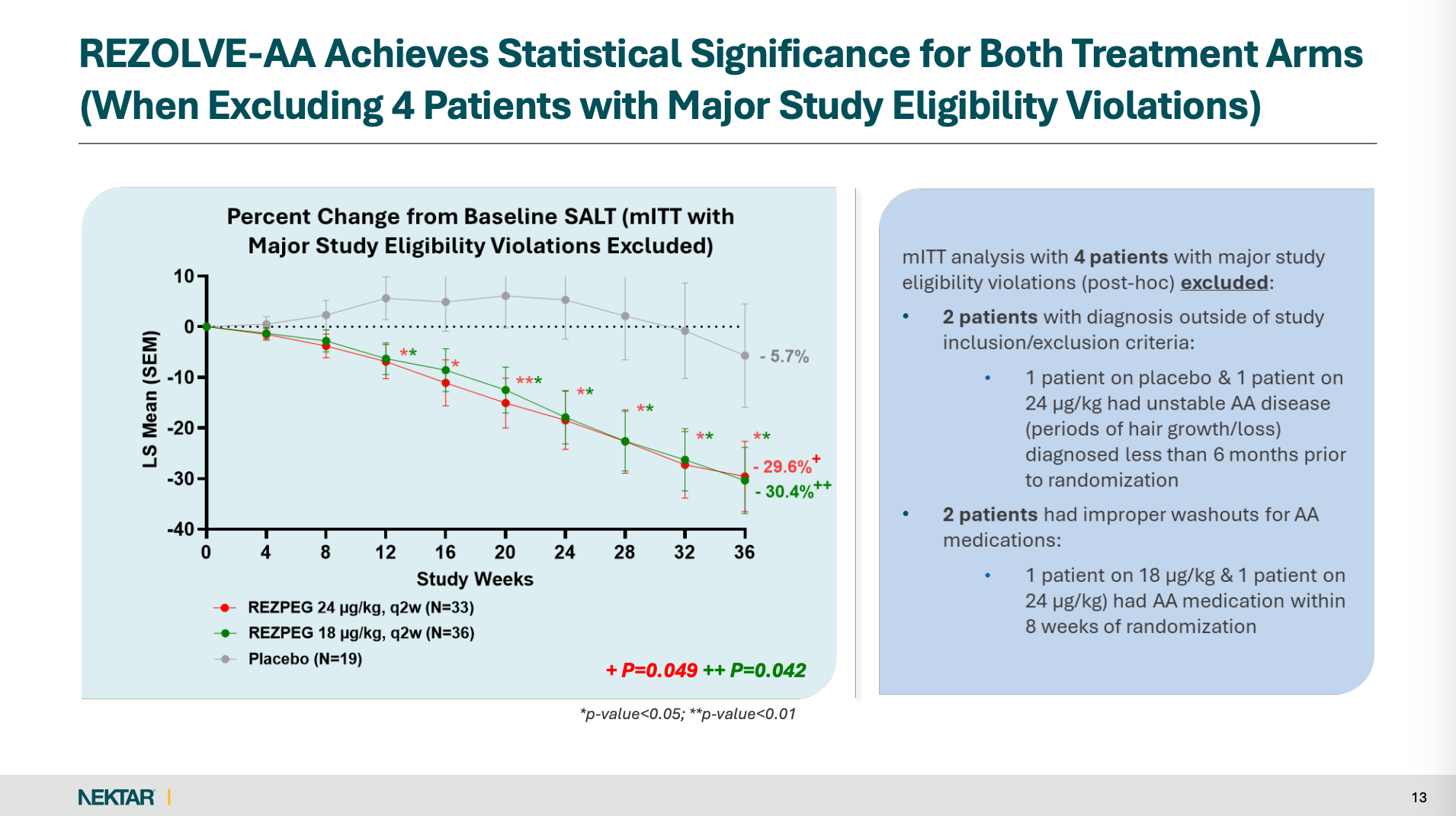
Post hoc rescue of the primary: The primary endpoint, which management unironically described as having “narrowly missed” in the prespecified mITT analysis (p=0.186; p=0.121), became nominally significant only after excluding four patients with “major eligibility violations” in a post hoc rescue (p=0.049; p=0.042).
Model-smoothed visuals (“clean lines”) can mask underlying noise: Several key plots are presented as LS means (SEM) from model-based analyses (MMRM with MI for missingness), not raw observed means. With ~40% discontinuation before Week 36 and only 11 placebo completers, the underlying observed data can be materially noisier and more selected than the smooth LS-mean trajectories imply. To be clear, plotting LS means (SEM) from a repeated-measures model is common for continuous longitudinal endpoints. My point is that the curves are potentially misleading in this specific context because of unusually high discontinuations (which makes later-visit estimates rely more heavily on modeling assumptions) and a prespecified approach where many post-discontinuation values are set to missing and handled via multiple imputation, with the continuous endpoint analyzed via MMRM.
Waterfall/“best response” presentation choices: The waterfall plot is explicitly labeled as “Best Percent Change in SALT from Baseline at All Timepoints” and is shown in the post hoc population excluding the 4 eligibility violators. It also notes that two patients in each Rezpeg group had no post-baseline assessment and are not included. These nuances can make the visual look much stronger than a prespecified Week 36 analysis.
Selection in the extension: The blinded extension is for patients who demonstrated hair growth, which structurally enriches later-week visuals for responders.
Conclusion
To wrap up, I am not saying definitively that MI/MMRM “manufactured” Rezpeg’s Week 36 result. I’m saying the combination of unusually heavy early attrition, management’s own admission (also implied by the waterfall plot) that discontinuation clustered among patients with limited early improvement, and a small, fragile placebo arm makes the headline continuous-mean treatment effect materially model-dependent and more likely to be overstated than understated.
Also bear in mind that press releases and corporate decks are curated summaries (akin to dating profiles), not full datasets. They naturally emphasize favorable framing, which is why missing-data assumptions, protocol deviations, and sensitivity analyses matter disproportionately here.
For investors, what’s most concerning, however, is Nektar’s insistence on pursuing a broad AA induction label despite mixed (at best) Phase 2 results. Simultaneously, its competitors (Sanofi’s and Regeneron’s DUPIXENT) are targeting the AA patients most likely to respond (those who have an atopic component or high IgE). In other words, REZOLVE-AA data (JAK/biologic-naïve + capped very severe + heavy single-country enrollment) does not provide a clean reproducibility template for a more robust and heterogeneous Phase 3, increasing the risk of indication failure and wasted capital. I’m speculating here, but it seems like management is being held hostage by the idea that Rezpeg can be a “pipeline-in-a-product.” Narrowing Rezpeg to just a subset of AA patients (e.g., atopic) or in other settings (e.g., post-JAK maintenance) is not supportive of this ongoing narrative.
Net-net, REZOLVE-AA was a classic “nothingburger,” and the market’s muted response can be interpreted in this light. The most likely outcome here is what was projected in my original Nektar article. While Rezpeg may be slightly active in AA, the signal reads more like a modest, selective effect than a durable, trial-ready profile.
Disclaimer: This publication is for informational and educational purposes only and does not constitute investment, tax, or legal advice. While I strive for accuracy, the information may be incomplete, inaccurate, or outdated, and is provided “as is” without any warranties. I do not hold positions in the stocks discussed unless explicitly stated otherwise. You are solely responsible for your own investment decisions; consider consulting a qualified financial professional before investing. Biotech and pharmaceutical stocks, in particular, are speculative and can result in substantial or total loss of capital.
Thank you for this fantastic analysis. The breakdown of how 'patient decision' dropouts flowed into the MMRM model, rather than being counted as failures, was a crucial catch. Your explanation of functional unblinding due to ISRs really connects the dots on why the data looks so fragile.
What do you think about Rezpeg for AD? And what do you expect for the 52-week maintenance data?